개요
- 각각의 상황에서의 저장시간을 비교해보며, 효율적인 방법을 찾아봅시다.
상황
- 1000개의 데이터를 데이터베이스에 넣는 상황으로 간주
Helper
- application.yml
server:
port: 8081
spring:
jpa:
hibernate:
ddl-auto: update
// 여기밑에 설정해줘야, Flush, Insert 갯수 카운트 가능
properties:
hibernate:
format_sql: true
dialect: org.hibernate.dialect.MySQL8Dialect
generate_statistics: true
show-sql: true- 실제 DB와 상호작용하는 Flush를 네트워크 I/O 비용으로 간주한다.
테스트
- 하기와같이 진행된다
- 트랜잭션 (X), saveAll(X), 배치 (X), 벌크 (X)
- 트랜잭션 (O), saveAll(X), 배치 (X), 벌크 (X)
- 트랜잭션 (O), saveAll(O), 배치 (X), 벌크 (X)
- 트랜잭션 (O), saveAll(O), 배치 (O), 벌크 (X)
- 트랜잭션 (O), saveAll(O), 배치 (X), 벌크 (O)
1번 상황 [ 트랜잭션 (X), saveAll(X), 배치 (X), 벌크 (X) ]
@Test
@DisplayName(value = "트랜잭션 (X), saveAll(X), 배치 (X), 벌크 (X)")
public void test1() {
Long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
Users user = new Users(
"username" + i,
"password" + i,
"email" + i + "@gmail.com"
);
userRepository.save(user);
}
Long end = System.currentTimeMillis();
log.info(" --- ");
log.info("test1 실행시간: {}", (end - start));
log.info(" --- ");
jpaQueryCount();
}2.2초가 소요된 모습이다.
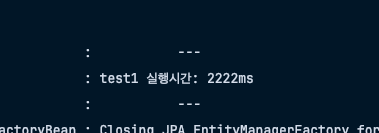
트랜잭션환경으로 묶여있지않기 떄문에, 영속성 컨텍스트에 데이터가 쌓이지않고, 개별적으로 처리되어 1000개의 FLUSH가 호출 되는 것을 알 수 있다
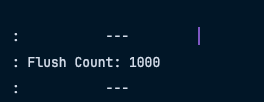
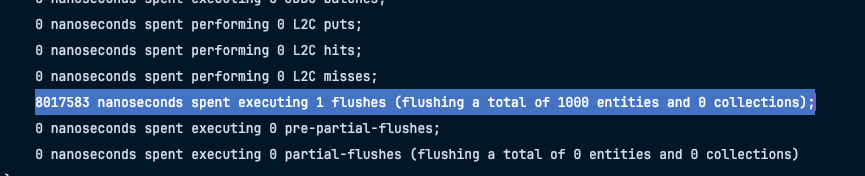
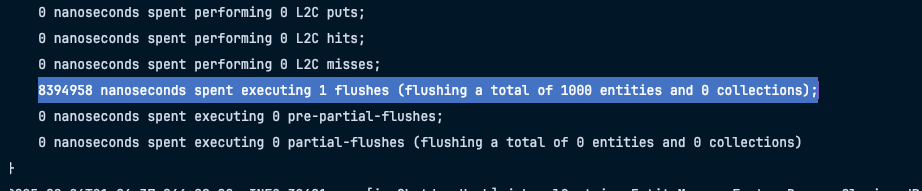
Flush가 총 1000번 일어난 모습이다.
2번 상황 [ 트랜잭션 (O), saveAll(X), 배치 (X), 벌크 (X) ]
@Test
@DisplayName(value = "트랜잭션 (O), saveAll(X), 배치 (X), 벌크 (X)")
@Transactional
@Commit
public void test2() {
Long start = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
Users user = new Users(
"username" + i,
"password" + i,
"email" + i + "@gmail.com"
);
userRepository.save(user);
}
Long end = System.currentTimeMillis();
log.info(" --- ");
log.info("test1 실행시간: {}ms", (end - start));
log.info(" --- ");
jpaQueryCount();
}0.6초가 소요된 모습이다.
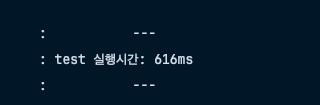
1000번의 쿼리가 하나의 트랜잭션으로 묶여있기떄문에, 커밋되는 시점에 한번에 DB에 저장되면서 네트워크 I/O비용이 1번만 발생한다.
3번 상황 [ 트랜잭션 (O), saveAll(O), 배치 (X), 벌크 (X) ]
@Test
@DisplayName(value = "트랜잭션 (O), saveAll(O), 배치 (X), 벌크 (X)")
@Transactional
@Commit
public void test3() {
Long start = System.currentTimeMillis();
List<Users> users = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
Users user = new Users(
"username" + i,
"password" + i,
"email" + i + "@gmail.com"
);
users.add(user);
}
userRepository.saveAll(users);
Long end = System.currentTimeMillis();
log.info(" --- ");
log.info("test1 실행시간: {}ms", (end - start));
log.info(" --- ");
}0.6초 소모로 2번 테스트케이스와 유사한 시간 속도를 보여준다
saveall역시 트랜잭션환경 안에서 호출되니 1번의 FLUSH만 호출하는 모습을 확인 할 수 있다
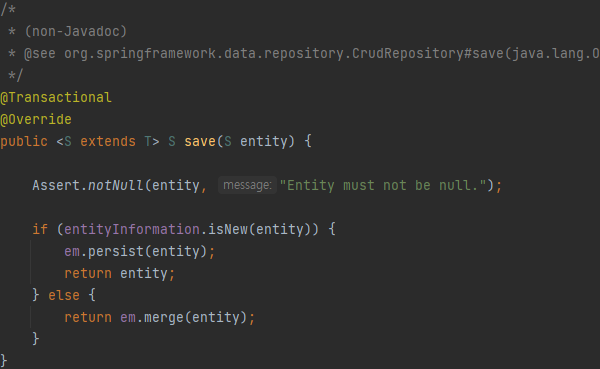
save vs saveAll
- save의 경우 for문으로 하나씩 넣어준다고 가정
- saveall의 경우 List<'Entity'>의 형태의 데이터를 넣어준다고 가정
- save
- 1번의 save가 호출될때마다, 상위 클래스의 트랜잭션환경이 있다면 전파받고, 없다면 새로 만들고, 저장을 한다
- 이러한 이유로 성능의 차이가 있는거군
- 1번의 save가 호출될때마다, 상위 클래스의 트랜잭션환경이 있다면 전파받고, 없다면 새로 만들고, 저장을 한다
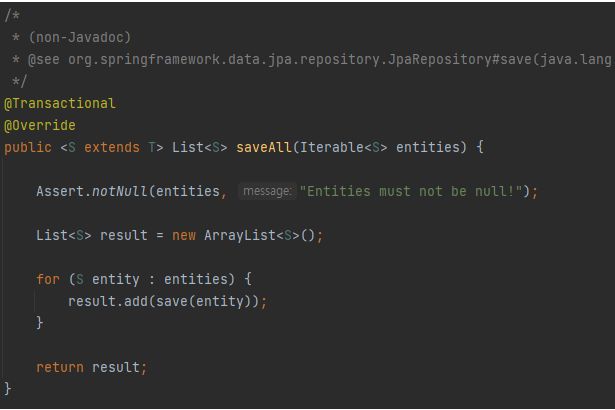
- saveall
- saveall을 호출한 클래스의 트랜잭션 환경이 있다면 전파받고, 내부에서 for문으로 자신의 클래스 내부에 있는 save메서드 호출(덕분에 새로운 프록시를 만들지않아도 되어 성능적으로 이득을 볼 수 있다)
4번 상황 [ 트랜잭션 (O), saveAll(O), 배치 (O), 벌크 (X) ]
- 배치할때는 auto_increment전략으로 IDENTITY가 되지않아, 잠시 시퀸스 전략으로 진행하였다.
@Test
@DisplayName(value = "트랜잭션 (O), saveAll(O), 배치 (O), 벌크 (X)")
@Transactional
@Commit
public void test4() {
Long start = System.currentTimeMillis();
List<Users> users = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
Users user = new Users(
"username" + i,
"password" + i,
"email" + i + "@gmail.com"
);
users.add(user);
}
userRepository.saveAll(users);
Long end = System.currentTimeMillis();
log.info(" --- ");
log.info("test 실행시간: {}ms", (end - start));
log.info(" --- ");
}- yml 파일 설정 추가
server:
port: 8081
spring:
datasource:
# url에 설정 추가
url: jdbc:mysql://localhost:3306/mydb?useSSL=false&serverTimezone=UTC&characterEncoding=UTF-8&rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999
username: user
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
dialect: org.hibernate.dialect.MySQL8Dialect
jdbc:
# 여기 밑에 배치 설정 추가
batch_size: 100
generate_statistics: true
show-sql: true
data:
redis:
host: redis
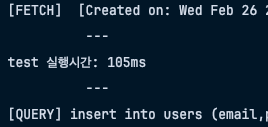
port: 6379- 0.1초 걸린 모습을 확인 할 수 있다
-
배치 Insert가 정상적으로 적용된 모습이다

1 FLUSH가 호출 되었다

배치사이즈 100에서, 1000개로 바꾸었을때의 속도는 하기와 같다.
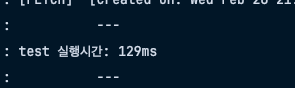
5번 상황 [ 트랜잭션 (O), saveAll(X), 배치 (X), 벌크 (O) ]
@Test
@DisplayName(value = "트랜잭션 (O), saveAll(X), 배치 (X), 벌크 (O)")
@Transactional
@Commit
public void test5() {
Long start = System.currentTimeMillis();
// 벌크 Insert 쿼리 준비
StringBuilder bulkInsertQuery = new StringBuilder("INSERT INTO users (username, password, email, id) VALUES ");
List<Users> users = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
users.add(new Users("username" + i, "password" + i, "email" + i + "@gmail.com"));
}
for (int i = 0; i < users.size(); i++) {
Users user = users.get(i);
bulkInsertQuery.append(String.format("('%s', '%s', '%s', DEFAULT)", user.getUsername(), user.getPassword(), user.getEmail()));
if (i < users.size() - 1) {
bulkInsertQuery.append(", ");
}
}
// 네이티브 쿼리 실행
em.createNativeQuery(bulkInsertQuery.toString()).executeUpdate();
Long end = System.currentTimeMillis();
log.info(" --- ");
log.info("벌크 Insert 실행시간: {}ms", (end - start));
log.info(" --- ");
}0.06초가 소요된 모습이다.
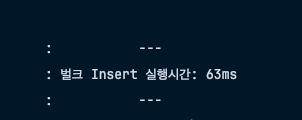
실행된 쿼리문
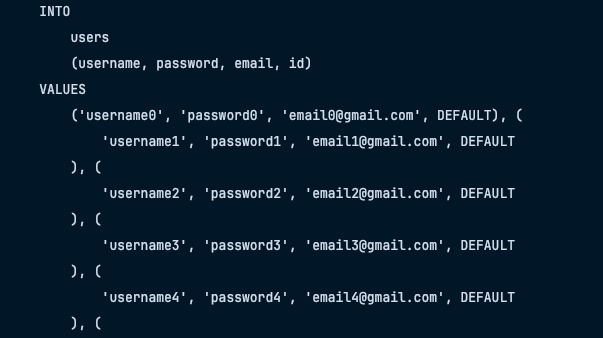
네이티브 쿼리 기반이다보니, flush count는 되지 않는 모습이다.

일단 오늘은 여기까지
- 벌크 연산에 대해서는 다음시간에 알아보자
참조 문헌
https://dev-coco.tistory.com/169
https://dkswnkk.tistory.com/682
TMI
- 테스트코드에서 트랜잭션환경이여야 롤백된다.
- JPA의 쿼리 로깅은 영속성 컨텍스트에 영속화될때 발생한다.
'SpringBoot' 카테고리의 다른 글
| JPA에서 ID 값이 NULL일 때와 존재할 때, INSERT vs UPDATE의 차이점 (0) | 2025.03.18 |
|---|---|
| 카카오 소셜 로그인시, CORS 문제 발생 (1) | 2025.03.13 |
| Redis에 엔티티 저장중 생긴 순환참조문제 (0) | 2025.01.23 |
| JSP 란? (1) | 2025.01.21 |
| JPA Cascade ? (2) | 2025.01.20 |