개요
- 자료구조에 대한 차이점을 구분하고 이해 할 수 있습니다
ArrayList의 가장 큰 특징과 그로 인해 발생하는 장점과 단점에 대해 설명해주세요
- 순차적으로 데이터를 저장함 (연속된 메모리공간을 유지)
- 장점
- 데이터에 순서가 있기때문에 0부터 시작하는 index가 존재하며, index를 사용해 특정 요소를 찾고 조작이 가능
- 단점
- 순차적으로 존재하는 데이터의 중간에 요소가 삽입되거나 삭제되는 경우 그 뒤의 모든 요소들을 한칸씩 뒤로 밀거나 당겨줘야함
- 이러한 이유로 Array는 정보가 자주 삭제되거나 추가되는 데이터를 담기에는 적절치 않습니다
- 특정 인덱스 접근:
- 삽입 (add):
- 중간삽입 (인덱스를 활용한)
- 삭제:
- O(N)
- [1,2,3,4,5] 라는 배열이 존재할때, 3을 없애버리면
- [1,2,-,4,5] 가되고, Array는 연속된 메모리 공간을 유지 해야하기 때문에
- [1,2,4,5,-] 가되면서, O(n)의 시간이 소요된다
Array를 적용시키면 좋을 데이터의 예를 구체적으로 들어주세요
- Array를 적용시키면 좋은 예시로 영화관의 좌석이 있습니다
- 고정된 좌석수에서, 순서가 중요하고 특정 Index의 자리를 빠르게 탐색 할 수 있습니다
Stack과 Queue
Stack
- LIFO (Last In First Out), 마지막에 들어간 원소가 처음 나오는구조
Queue
- FIFO (First In First Out), 처음 들어간 원소가 처음 나오는 구조
Tree와 Heap
Tree
- 비선형 자료구조
- 계층적 관계를 표현하기에 적합
Heap
- 최댓값 또는 최솟값을 찾아내는 연산을 쉽게 하기위해 고안된 구조
- 각 노드의 키값이 자식의 키값보다 작지않거나(최대힙), 그 자식의 키값보다 크지 않은(최소힙) 완전이진트리
Stack과 Queue의 실사용 예를 간단히 설명해주세요
Stack
- LIFO
- 웹브라우저의 뒤로가기 기능
- 새페이지를 방문할떄 Stack에 쌓이고
- 뒤로가기 버튼을 눌렀을떄 맨마지막에 Stack에 쌓인(바로 최근에 누른 새페이지)를 pop하고 이전페이지로 이동
Queue
- FIFO
- 프린터 작업 대기열
- 먼저 요청받은 용지를, 먼저 처리하는 방식
Priority Queue(우선순위 큐)에 대해 설명해주세요
- 들어간 순서에 상관없이 우선순위가 높은 데이터를 먼저 꺼내기 위해 고안된 자료구조
- 우선순위 큐 구현 방식에는 배열,연결 리스트(Linked List), 힙이 있고, 그 중 힙 방식이 worst case라도
시간 복잡도 O(log n)을 보장하기 때문에 일반적으로 완전 이진 트리 형태의 힙을 이용해 구현합니다
Array와 ArrayList의 차이점
- ArrayList도 내부적으로는 Array에 기반하여 동작되기 때문에, 기존 배열 갯수를 초과하여 데이터를 넣지않는 이상까지는 동일하다
Array
- 크기가 고정적
- 초기화시 메모리에 할당되어 속도가 빠름
- Ex)
- 크기가 4인 배열이 존재
- append를 통해 4개까지 삽입가능
ArrayList
- 크기가 가변적
- 데이터 추가 및 삭제시 메모리의 재할당으로 인한 속도의 느림
- Ex)
- 크기가 n인 가변배열 존재
- add를 통해 데이터를넣고, n개를 초과할경우
- 새로운 배열 (기존 배열보다 큰)을 만든다 -> 기존 배열의 데이터를 새로운 배열에 옮긴다 -> add를 통한 데이터를 추가 하는 방식
Array와 LinkedList의 장/단점
Array
LinkedList
- 비연속적인 메모리 특성
- 장점:
- 단점:
- 각 노드는 포인터로 연결되어있어, 특정 위치의 데이터를 찾기위해 첫 노드부터 탐색해야하므로, O(n)의 연산수행이 소요된다
- 노드1을 통해야만, 노드2로 갈 수 있고
- 노드2를 통해야만, 노드3를 갈 수 있다는 의미이다
Test (조회)
package 리스트;
import java.util.ArrayList;
import java.util.LinkedList;
public class ExamList {
public static void main(String[] args) {
LinkedList<Integer> linkList = new LinkedList<>();
ArrayList<Integer> list = new ArrayList<>();
for ( int i=0; i<10000000; i++ ) {
linkList.add(i);
list.add(i);
}
long start = System.nanoTime();
linkList.get(9999999);
long end = System.nanoTime();
System.out.println("링크 리스트 조회 시간" + (end - start) + "ns");
start = System.nanoTime();
list.get(9999999);
end = System.nanoTime();
System.out.println("일반 리스트" + (end - start) + "ns");
}
}
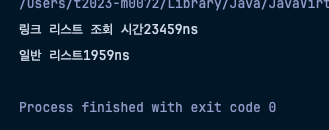
- 확실히 Array에 기반한 List의 속도가 더욱 빠른것을 알 수 있다
- 다음은 삭제 속도를 비교해보자
Test (삭제)
package 리스트;
import java.util.ArrayList;
import java.util.LinkedList;
public class ExamList {
public static void main(String[] args) {
LinkedList<Integer> linkList = new LinkedList<>();
ArrayList<Integer> list = new ArrayList<>();
for ( int i=0; i<10000000; i++ ) {
linkList.add(i);
list.add(i);
}
long start = System.nanoTime();
linkList.remove(555555);
long end = System.nanoTime();
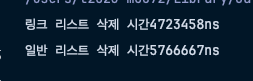
System.out.println("링크 리스트 삭제 시간" + (end - start) + "ns");
start = System.nanoTime();
list.remove(555555);
end = System.nanoTime();
System.out.println("일반 리스트 삭제 시간" + (end - start) + "ns");
}
}
Test (중간삽입)
package 리스트;
import java.util.ArrayList;
import java.util.LinkedList;
public class ExamList {
public static void main(String[] args) {
LinkedList<Integer> linkList = new LinkedList<>();
ArrayList<Integer> list = new ArrayList<>();
for ( int i=0; i<10000000; i++ ) {
linkList.add(i);
list.add(i);
}
long start = System.nanoTime();
linkList.add(555555,99);
long end = System.nanoTime();
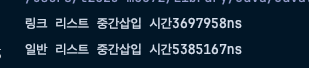
System.out.println("링크 리스트 중간삽입 시간" + (end - start) + "ns");
start = System.nanoTime();
list.add(555555,99);
end = System.nanoTime();
System.out.println("일반 리스트 중간삽입 시간" + (end - start) + "ns");
}
}
Hash Table
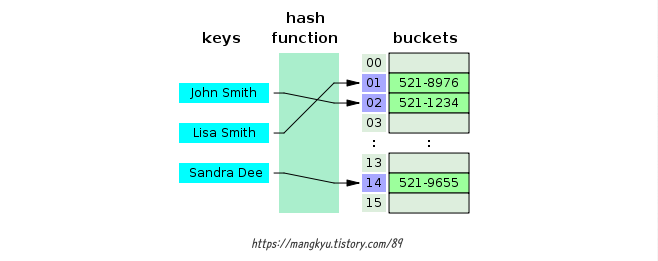
- 데이터를 key-value 쌍으로 저장하는 자료 구조
- 데이터를 빠르게 삽입,삭제,검색 할수있도록 설계되었으며, 해싱이라는 방식을 사용하여 데이터를 저장하고 조회합니다
- 해시 함수
- key를 받아 고유한 정수 (해시코드)로 변환
- 이 해시코드가 내부적으로 인덱스 역할을하여 O(1)의 검색조회속도가 가능하다
Test
package 맵;
import java.util.Hashtable;
public class ExamMap {
public static void main(String[] args) {
Hashtable<String, Integer> map = new Hashtable<>();
map.put("One",1);
map.put("Two",2);
map.put("Three",3);
}
}
- 위와같은 코드는 아래와 같은 형태로 저장되어있다
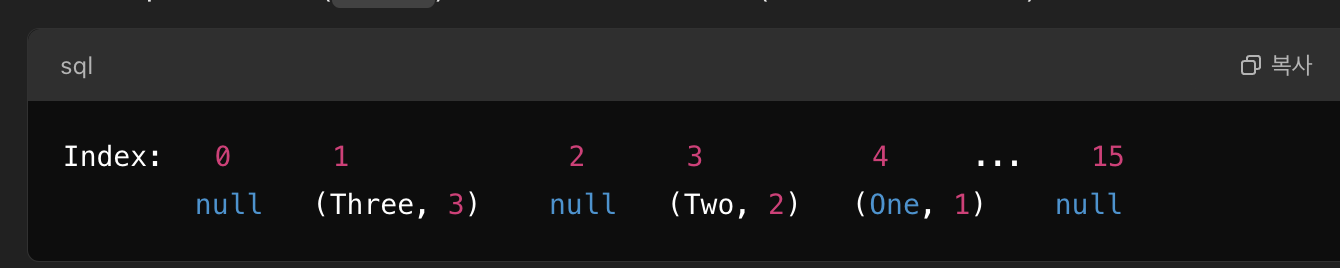
- One이라는 키의 value를 찾는 흐름은 아래와 같다:
- One의 hashCode() % 16 = 4
- 여기서 16은 HashMap의 내부 배열 크기 (기본값: 16)다.
- Index 4에 접근 (O(1))
- Index 4에 저장된 데이터는 "버켓(Bucket)"에 저장되어 있다.
- 버켓은 기본적으로 연결 리스트 또는 Red-Black Tree로 구현된다.
- 버켓 내부에서 One이라는 키를 찾기 위해 키를 비교하며 탐색.
- 최악의 경우 O(n)의 시간 복잡도가 발생한다.
- Java 8 이후, 연결 리스트가 8개 이상이면 Red-Black Tree로 변환되어 탐색이 O(log n)으로 최적화된다.
- 키가 One과 일치하는 데이터를 찾으면 해당 value를 반환한다.
Red Black Tree?
- BST를 기반하여 만들어진 Tree
- 각 노드의 색깔을 빨강,검정으로 구분짓는다
- 빨강 노드가 연속 두번으로 나오면 규칙을 위반하였다고 판단 (트리가 한쪽으로 치우쳐졌다고 판단)
- 트리를 재조정하는 형식이다
HashMap과, HashTable의 차이점
BST, BT에 대해 설명해주세요
- BT (Binary Tree - 이진 트리):
- 자식 노드가 최대 두개인 노드들로 구성된 트리
- BST (Binary Search Tree - 이진 탐색 트리)
- 이진탐색 + LikedList를 결합한 자료구조
- 검색할때의 시간복잡도는 O(h)
- 트리가 치우쳐진 worst case의 경우 O(n)까지 소요될 수 있음
- 이러한 worst case의 BST를 막기위한 Tree가 RBT(Red-Black-Tree)다
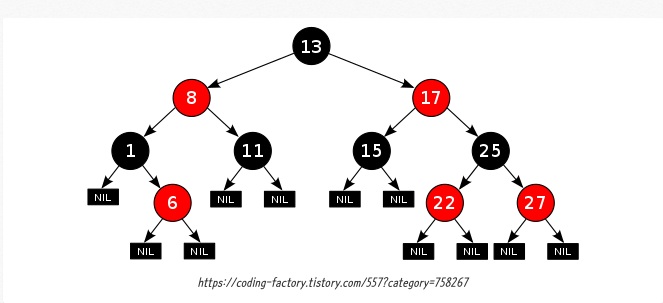
RBT에 대해 설명해주세요
- 자기 균형 이진 탐색 트리
- BST에 기반한 Tree 형식 자료구조
- BST의 삽입,삭제 연산과정에서 발생할 수 있는 문제점을 만들기위해 만들어짐
- BST의 특징을 모두 가지고 있음
- 노드의 child가 없을 경우, child를 가리키는 포인터는 NIL값을 저장
- 이러한 NIL들을 leaf node로 간주
- 모든 노드를 Red or Black으로 색칠하며, 연결된 노드들은 색이 중복되지 않음
- 항상 균형상태를 유지하여 최악의 경우(worst case)에서도 O(log n)을 유지
참조 문헌
https://dev-coco.tistory.com/159